핵심 키워드: one class SVM, anomalies detection, outlier detection, deep learning
ABSTRACT
OCNN (one class neural network) 모델은 복잡한 데이터셋에서 이상점을 검출하기 위해 제안된 모델이다. 이 모델은 NN(neural network)와 one class SVM(support vector machine)을 결합한 모델로 히든 레이어에서 data representation을 FFNN(feed forward neural network)을 통해서 나타냈다. 이는 feature를 오토인코더를 통해서 학습하고 OC-SVM 같은 이상점 검출 모델에 feature를 넣어주는 다른 모델들과 다른 방식으로 진행한다는 것을 의미한다.

[문제점]
기존 방식인 auto-encoder를 통해 feature를 학습하고 feature를 OC-SVM에 넣어서 이상점을 검출하는 방법이 가진 문제점은 히든 레이어에서의 유의미한 특징 학습이 불가능하다는 점이다.
[해결방안]
따라서 논문에서는 OC-SVM과 동일한 역할을 하는 뉴럴 네트워크 모델을 새로 제안한다.
(deep network를 통해 점점 풍부한 데이터 특징을 학습하고 OC-모델을 통해 정상 데이터를 origin에서 분리시킨 하이퍼플레인을 얻어낸다.)
쉽게 말해서 OC-SVM 같은 loss function으로 학습한다.
[논문의 contribution 요약]
- one class neural network model 개발 및 제안을 위한 실험
- minimization 알고리즘을 OCNN 모델 학습 파라미터 방법으로 제안
(OCNN의 subproblem이 분위면을 선택하는 문제와 동일하므로)
Background
[Robust Deep Autoencoder]
참고논문: https://www.eecs.yorku.ca/course_archive/2017-18/F/6412/reading/kdd17p665.pdf
RDA(Robust Deep Autoencoder)나 RCAE(Robust Deep Convolutional Autoencoder)는 input data X를 LD와 S로 분리한다.
LD은 오토 인코더 내부의 잠재 공간을 의미하고 matrix S는 reconstruct가 어려운 아웃라이어나 노이즈를 잡아낸다.
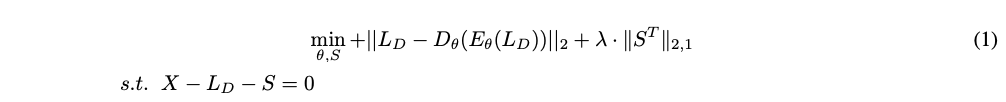
RDA는 RPCA(Robust Principal Component Analysis) + Deep Autoencoder로부터 설계되었다.
[RDA]
자세하게 리뷰하진 못했고 위의 식이 대강 어떤 식이고 어떻게 파생됐는지 정도만 이해하기 위해 작성해 보았다.
RPCA(Robust Principal Component Analysis)는 input data를 저 차원 행렬 L과 희소행렬 S로 분리한다. 이 행렬 분해는 아래와 같은 식을 최적화하는 문제가 되는데 P(L)은 L의 rank 개수로 ||S0||는 S에 0이 아닌 entry의 개수로 바꾸고 Frobenius norm을 적용한 것으로 대체할 수 있다. 자세한 사항은 논문에 참고사항을 보면 된다!
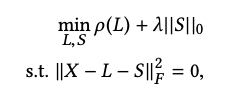
하지만 위의 식은 NP-hard 하다.(튜링 머신으로 polynomial time 내에 답을 구할 수 없다) 따라서 아래와 같은 식으로 변경하는데
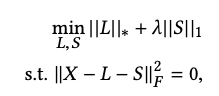
L에 대한 SVD의 합인 nuclear norm과 각 엔트리의 절댓값의 합의 문제로 볼 수 있고 이것을 통해서 논문에서는 nuclear norm을 저 차원 hidden layer에 linear projection 하는 non-linear autoencdoer로 대체하였다.
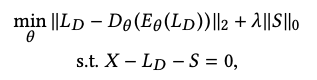
RDA에서는 input data X를 히든 레이어에서 나타내는 input data LD와 reconsturct가 어려운 아웃라이어나 노이즈로 분리한다. X에 노이즈를 제거하게 되면 LD를 더 완벽하게 복구하게 된다. 따라서 수식은 아래와 같이 X - LD - S = 0을 충족하는 식을 계산하는 것인데 이것은 최소화하는 것으로 볼 수 있고 input LD를 인코딩 후 디코딩 한 값이 기존 LD와 얼마나 차이가 나는가를 따지는 문제로 변하고 l0 norm은 l1 norm으로 위에 RPCA 때와 같이 변형할 수 있다. 그럼 아래 식이 나오는데
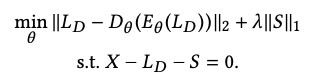
이것은 noise나 outlier가 군집화되어있지 않다고 가정했지만 실제로는 구조화된 경우가 많다. 따라서 우리는 2가지 문제를 해결해야 한다.
- 특정 feature가 손상된 경우 (ex: 카메라 이미지 중 한 픽셀이 망가진 경우)
- 다른 feature와 다른 feature가 있는 경우 (ex: 2가 모여있는 곳에 7이 하나 들어 있는 경우)
위의 경우들을 해결하기 위해 S 플레인에 group penalty l2,1 norm을 적용시켰다. 만약 row를 그룹화한 것 중에서 anomaly를 찾고 싶다면 S에 transpose를 취한 값(ST)으로 계산을 하면 된다.
 |
 |
[OC-SVM]
RKHS 참조 링크: https://lee-jaejoon.github.io/stat-rkhs/
oc-svm 참조 논문: https://proceedings.neurips.cc/paper/1999/file/8725fb777f25776ffa9076e44fcfd776-Paper.pdf
oc-svm 참조 유튜브: https://youtu.be/OmK_GQ40yko
one-class SVM은 SVM과 다르게 비지도 학습(unsupervised learning)이다. 주어진 데이터를 원점에서 가장 멀리 떨어뜨리는 하이퍼플레인을 찾는 SVM이며 RKHS(reproducting kernel Hilbert space)를 사용한다. 이로 인해 OC-SVM은 모든 데이터들이 +라벨을 가지게 되고 원점은 유일한 -라벨이 된다.

0 <= v <= 1
첫 번째 텀은 l2 regularization에 해당하고 같은 값이라면 x값의 변동이 크지 않게 하기 위해서 사용한다. (모델의 변동성 감소)
두 번째 텀은 경계면의 조건을 만족하지 못하는 정상 데이터에 penalty 부여
세 번째 텀은 r(ro)를 찾는데 원점에서 최대한 멀리 떨어진 hyper plane과의 거리를 의미한다.
가장 멀리 떨어진 r을 찾기 위해 min 중인 목적함수에서 -로 삽입 되어 있다.

OCNN
3.1 OCNN (1-neural network, one-class neural network)

W: 히든 레이어의 결과값을 받아온 스칼라 값
V: input에서 히든 레이어 유닛까지의 weight matrix
ν: 0과 1사이의 값으로 원점으로부터 hyper plane까지의 거리와 정상 샘플 영역의 크기 간에 trade-off를 제어하는 매개 변수
<W, g(VXn:)>: OC-SVM에서 <W, ϕ(Xn:)>을 변경하였는데 sigmoid activation으로 감싸고 weight matrix를 곱해주었다.
위 수식 변화로 가져오는 일
- 오토 인코더를 통해 얻은 feature를 transfer learning(전이학습) 할 수 있게 된다.
- 이상점 검출을 위해 추가적인 레이어를 추가하거나 개선할 수 있게 된다.
- objective function이 non-convex 형태를 띄게 된다.

3.2 Training the model
train을 하기 위해 r(ro)를 w와 V로 최적화하는데 이것은 v 배열의 분위수(quantile)와 같다.





