Abstract
비디오 이상점 검출(Video Anomaly Detection)은 시간이 오래 걸리는 연구이다.
동적인 장면들이 있는 1인칭 교통 영상들은 효과적인 평가지표뿐만 아니라 대규모의 벤치마크 데이터셋도 부족하다.
이 논문에서는 비정상적인 이벤트를 감지, 로컬라이제이션, 인식하기 위해 언제 어디서 어떤 파이프라인을 통해 traffic anomaly detection을 할지 제안한다.
논문에서는 Detection of Traffic Anomaly (DoTA)라는 시간,공간, 18개의 카테고리에 관한 annotaition이 담긴 4677개의 비디오를 가진 데이터셋을 소개한다. DoTA 데이터셋에서는 Spatial-Temporal Area Under Curve(STAUC)라는 새로운 평가방법을 적용시켰고,
이 평가 방법은 실험에 의해 VAD 차원에 효과적임을 보였다.
1. Introduction
ADAS(첨단 운전자 보조 시스템)에서는 사고 상황에 대한 정확한 인식이 주요한 쟁점이다.
사고가 발생할 것인가? 누가 연류될 것인가? 어떤 형태의 사고가 날 것인가?
이 주요한 질문들은 도로 위에 이상 상황에 대한 적절한 대응과 사건 데이터 기록을 위한 분류와 인식, 로컬라이제이션에 영향을 준다.
그래서 논문에서는 When-Where-What 파이프라인을 제안하는데 담고 있는 의미는 아래와 같다.
언제 이상 상황이 시작되고 끝나는가? 비디오 프레임 어디서 이상 지역이 검출되는가? 어떤 이상 상황인가?
이 파이프라인은 비디오 속 이상점 검출(VAD)과 비디오 속 행동 분류(VAR) 2가지 일로 연결된다.
VAD는 언제라는 질문에 대답하기 위해 프레임별 이상점 점수에 정답을 예측하고 어디서라는 질문에 얼추 대답하기 위해 픽셀별 이상 점수나 물체별 이상 점수를 계산한다.
VAR은 무엇을에 답하기 위해 비디오 타입 분류를 한다.
특히 DoTA는 카테고리, 시가 annotation과 이상 물체 bounding box 정보 등 풍부한 annotation을 가지고 있어 VAD 행렬 평가 방법으로 이점을 취하기 위해 STAUC를 AUC의 상위호완으로 제안한다.
AUC는 프레임별 이상 점수를 픽셀 단계나 물체 단계에 매핑된 점수를 평균내어 계산하는데 반해, STAUC는 그것들과 함께 annotated된 이상 지역과 얼마나 겹치는가를 계산한다. 이 겹치는 비율은 정답을 예측하는데 weighting factor로 사용된다.
파이프라인을 완성하기 위해 VAR의 최신 기법(R2+1D나 SlowFast)를 Dota에 적용시켜보았는데, 일반적인 VAR 기법은 traffic anomaly를 이해시키는데 적절치 않다는 것을 보였고, 이 분야가 더 많은 연구를 하기 적합한 분야임을 알게 되었다.
적용시킨 VAR( TSN, TRN, C3D, R(2+1)D, RED, GAN )
3. The Detection of Traffic Anomaly (DoTA) Dataset
DoTA는 유튜브 채널에서 가져온 다양한 날씨, 조명, 국가, 카메라로 이루어진 6000개 이상의 비디오 클립을 수집했다.
윈드 실드에서 카메라가 떨어지거나 가려져 사고가 보이지 않는 영상을 제외하고 1280x720의 해상도로 4677개의 영상을 얻었다.
영상의 원본 프레임은 30fps이나 annotation과 실험을 위해 10fps으로 추출하였다.
표1. 다른 데이터셋과의 비교

그리고 각각의 영상은 12명의 다른 운전 경험을 가지고 있는 annotator에 의해 labeling되었고, 3명의 annotator가 labeling한 것에 대해 평균을 취했다.
Temporal Annotations
이상 행동 전 정상 비디오, 이상행동, 이상행동 이후 정상 비디오로 나누어져있다.
조기에 이상점을 검출하는 것이 중요하므로 이상점이 예상되는 순간을 시작으로 잡았다.
(이상 행동 계체의 절반이상이 화면에 나오는 순간으로 잡으면 등장 이후 시간이 한참 흐른 후 사고가 나는 경우에 너무 일찍 라벨링하기 때문, 또한 사고가 난 이후로 잡으면 조기 검출이 불가능하다.)
모든 이상 계체가 정지하거나 화면 밖으로 나가는 순간을 종료시점으로 잡았다.
사진3(a) duration 분포

Spatial Annotations
이상 행동 시작부터 화면 밖으로 나가는 순간까지 고유 tracking ID로 labeling 하였다.
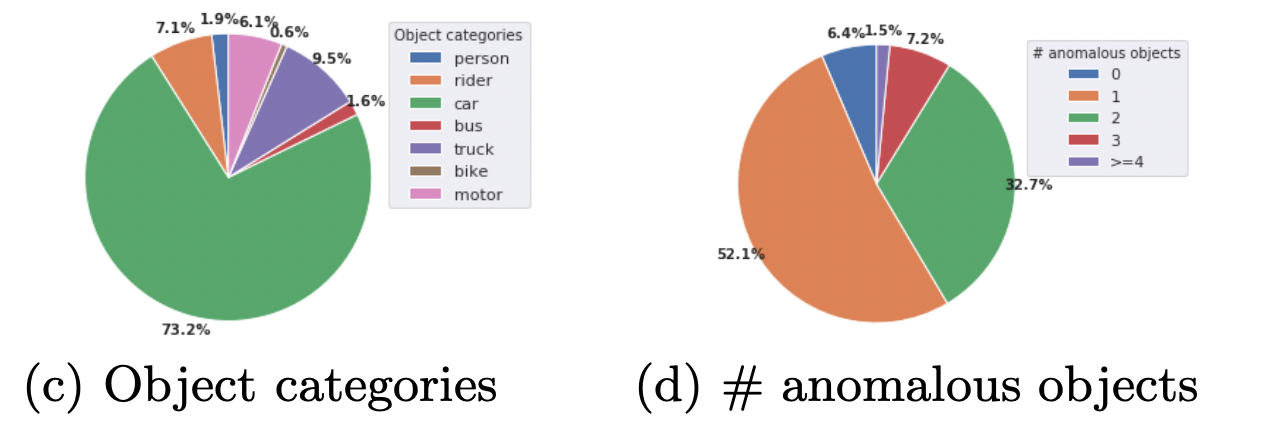
카테고리로는 사람, 차, 트럭, 버스, 오토바이, 자전거, 라이더 7개로 잡았다.
사진3(c,d) 카테고리별 물체 비율과 이상물체 갯수 비율
4. Video Anomaly Detection (VAD) Methods
supervised VAD와 unsupervised VAD(프레임레벨) 모두 벤치마크 하였음.
Frame-level Unsupervised VAD

이 방법은 이전 프레임을 복원하거나 이후 프레임을 예측하고 예측 오차를 재현한다. 이 논문에서는 3가지 방법을 벤치마크했다.
방법1. ConvAE: spatio-temporal autoencoder 모델로 2차원 convolutional encoder로 임시로 쌓인 이미지를 인코딩하고 deconvolutional layer로 디코드해 이미지를 재구성하는 방법.

픽셀당 재구성 오류는 annomaly score map i를 형성하며 MSE는 프레임 레벨에서 이상점 점수로 계산
방법2. ConvLSTMAE: ConvAE랑 비슷한데 시간과 공간 특징을 분리해서 사용. 2차원 CNN 인코더가 프레임당 공간정보를 먼저 포착한 후 multi-layer ConvLSTM이 반복적으로 시간 정보를 인코딩한다.
방법3. AnoPred(Masked-RCNN, AnoPred+Mask): 4개의 연속적인 이전 RGB프레임을 input으로하여 이후 RGB 프레임을 예측하기 위해 UNet을 적용. 이미지 강도, optical flow, 기울기, adversarial losses 등을 포함하는 multitask loss를 사용하여 예측 정확도를 높였다.
Object-centric Unsupervised VAD
방법1. TAD: multi-stream RNN encoder-decoder를 사용해서 교통 상황에 정상 bounding box의 궤도를 모델링해서 과거의 궤도와 스스로의 모션을 인코딩하고 미래 물체 bounding box를 예측한다.
여기서는 예측 결과가 수집되고 정확성 대신 예측의 일관성이 anomaly 점수를 계산하는데 사용되고, 객체당 점수로 평균을 내서 프레임당 점수를 낸다. 개선으로 TAD+ML이라는 것도 나와서 사용했음.
방법2. Ensemble: 앞에서 보인 frame-level에서 물체의 appearance에 초점을 맞추고 object-centric에서 물체 움직임에 초점을 맞췄더니 appearance는 조명의 다양한 변화에 취약하고 움직임은 궤도가 불안정할 때 취약하다. 그래서 AnoPred+Mask and TAD+ML, 합쳤다. 늦게 합치는게 일찍 합치거나 함께 학습시키는 것보다 성능이 좋았다.
Supervised VAD as Online Action Detection
pretrained로 ResNet50 사용,
방법1. FC: 3개의 fully connected network로 이루어진 이미지 분류기
방법2. LSTM: 1개의 LSTM으로 sequential image 분류
방법3. Encoder-Decoder: LSTM모델에 현재 프레임을 인코딩하고 예측 클래스를 디코딩
방법4. TRN: 인코더 디코더 기반으로 진행
'AI' 카테고리의 다른 글
| [VAE] Auto-Encoding Variational Bayes 리뷰 (0) | 2022.11.23 |
|---|---|
| DAY4 (0) | 2022.07.08 |
| [Day3] (0) | 2022.07.06 |
| Learning 종류 (0) | 2022.07.04 |