ABSTRACT
폭발적인 비디오 스트리밍의 증가는 비디오 understanding에 대한 높은 정확도와 낮은 계산비용에 도전을 불러왔다.
2D CNN은 계산비용이 적지만 시간적인 정보는 가져오지 못한다; 3D CNN은 계산집약적이여서 비용이 만만찮다.
따라서 위 논문에서는 일반적이고 효과적인 Temporal Shift Module 을 고성능과 고효율 모델로 추천한다.
TSM은 2d의 복잡도로 3D의 퍼포먼스를 낸다. 전형적인 서론...
TSM은 시간축을 따라 채널의 일부를 이동시킨데 이것 덕분에 인접 프레임과 정보 교환이 쉬워진다.
It can be inserted into 2D CNNs to achieve temporal modeling at zero computation and zero parameters. 라는 말이 있었는데 'TSM을 2D CNN에 추가시키면 시간축 모델링을 만들면서 추가적인 계산이나 파라미터는 없다.' 라고 이해했습니다.
그리고 저자는 온라인 세팅에도 TSM을 확장 시켜서 라이브 스트리밍 비디오 지연시간에도 비디오 object를 발견하고 인식할 수 있도록 확장 시켰다고 합니다. 자세한 real-time low-latency online video에 관한 설명은 아래 링크를 첨부합니다.
https://weandstory.tistory.com/167
유튜브의 라이브 스트리밍 지연시간
스트림 지연시간(레이턴시)는 카메라가 이벤트를 캡쳐한 후 그 이벤트가 사용자에게 표시되기까지 걸리는 시간입니다. 유튜브에서 라이브 스트림을 사용하고자 할 때, 이 지연시간이 시청자에
weandstory.tistory.com
Introduction
과거에 시간축 모델링과 연산능력을 절충하려는 시도가 있었다. (ex. post-hoc fusion 사후검정 퓨전, mid-level temporal fusion)
이 방법들은 효율성을 위해 로우 레벨에서의 시간축 모델링을 희생시키지만, temporal fusion이 발생하기 전에 대부분의 중요한 정보가 추출 중에 손실된다.
그래서 저자는 Temporal Shift Module(TSM) 을 제안한다.
구체적으로 비디오 모델에서 activation function(활성함수) 는 아래와 같이 나타날 수 있는데
A ∈ R ^ (N × C × T × H × W)
N은 배치사이즈, C는 채널의 갯수, T는 시간 차원, H와 W는 공간의 해상도를 의미한다(width, height)

그림(a) : 전형적인 2D CNN이며 시간축에 각각 독립적으로 convolution 시켜서 어떤 시간적 모델링이 적용되지 않는다.
그림(b) : TSM이며 시간축의 앞이나 뒤로 채널을 이동시킨다. 이동 후엔 현재 프레임과 인접 프레임의 정보가 섞이게 된다.
컴볼루션은 shift(이동) 과 multiply-accumulate (곱셈 연산)으로 이루어져있는데 이것을 이용하여 시간 차원에서 채널 차원까지 multiply-accumulate을 fold한다. (겹친다? 접는다?)
그림(c) : 그런데 실제 세상에서는 미래 프레임이 현재 프레임에 이동될 수 없으므로 uni-directional TSM을 사용했고 온라인 비디오에 사용했다.
연산을 늘리지 않는 shift operation의 장점에도 불구하고, 단순하게 이미지 분류에 이 전략을 사용하는 것이 비디오 이해에 2가지 문제를 야기하는 것을 알게 되었다.
[문제]
1. 이동 연산(shift operation)은 거의 0에 가까운 연산이지만 데이터 이동을 발생시킨다.
- 데이터 이동에 대한 추가적인 비용은 latency 증가를 가져오므로 무시할 수 없다.
- 이 현상은 주로 많은 메모리를 사용할 때(5D activation) 악화되었다.
2. 부정확성
- 너무 많은 채널 shifting은 공간 모델링을 크게 손상시키고 성능 저하로 이어진다.
[해결책]
1. 부분적인 시간축 이동 전략 (Temporal partial shift strategy)
- 효율적인 temporal fusion을 위해 모든 채널을 시프팅하지 않고 일부분의 채널만 시프팅한다.
- 이 전략은 데이터 이동 비용을 상당히 감축시킨다.
2. TSM을 residual branch 밖보단 안에 넣어서 현재 프레임의 activation을 보존한다.
- 이로써 2D CNN 베이스의 공간 학습 능력을 해치지 않는다.
[논문의 contribution 요약]
- 연산량은 증가하지 않지만 강력한 시공간 모델링 능력을 가진 Temporal shift를 통해 새로운 관점을 제시
- 단순한 시프팅은 성능 향상을 하지 못하며, partial shift 와 residual shift를 통해 높은 효율을 낼 수 있음을 발견
- Something-Something 에서 가장 좋은 능력을 보인 오프라인 양방향 TSM을 제안
- Edge device 에서 낮은 latency에 강력한 시간 모델링 능력을 가진 TSM을 제안
TSM
[Intuition]
W = (w1, w2, w3)
The convolution operator Y = Conv(W, X )
can be written as:

이 컨볼루션(convolution)을 shift와 multiply-accumulate 2가지 스텝으로 나눌 수 있는데 여기서 X를 -1, 0, 1만큼 shifting 시킨다.
그러면 shifting 연산 값은 아래와 같은데
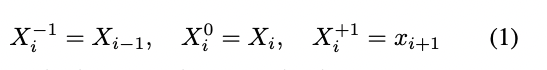
이것에 W를 각각 순서대로 곱하고 합하면 Y가 된다.

첫 단계에 shift는 따로 계산 없이 실행될 수 있는데 2 단계에서 연산량이 많으므로 TSM은 multiply-accumulate을 먼저 한 후 다음 2D convolution에 합쳤고 이것은 2D CNN 기존 모델에 추가적인 연산이 들지 않는 것과 같게 만들었다.
말이 좀 복잡한데 Conv을 shift와 m-a 로 나눌 수 있고 그렇게 나누면 맨 위에 Y = 식이 생성됩니다.
이것을 (1) 과정과 같이 shifting 하고 multiply-accumulate 를 하는 과정으로 나눌 수 있고 multiply-accumulate 하고 다음 2D convolution 결과 값에 합치므로 기존 모델에 비해 추가적인 연산 비용이 들지 않는 것입니다.
이것을 맨 위에 있는 그림 1에 적용시키면 각 채널의 부분을 -1 0 1 하며 움직이는 모습이라고 이해하시면 됩니다.
[Naive Shift Does Not Work]
이유는 위에 설명한 것과 같이 (1) 많은 데이터 이동 때문에 비효율적 (2) 공간 모델링을 망쳐 성능이 저하됨에 대해서 다룹니다.
[Module Design]
1. Reducing Data Movement
- ResNet-50, 8프레임 input 기준으로 (1/8, 1/4, 1/2, 1/1 shift channel)을 시도하였습니다.
2. Keeping Spatial Feature Learning Capacity
- 기존에 shift하고 conv layer 이전에 TSM을 적용시키면 기존 프레임에서 많은 양의 채널을 shift할 때 그 만큼 현재 프레임에 빈 공간이 생기므로 spatial feature learning에 문제가 생겼습니다.
- 따라서 residual block 안에 residual branch에 값을 넣게 된다. 그렇게 하면 기존 값을 계싼하고 다음에도 사용할 수 있기 때문입니다.

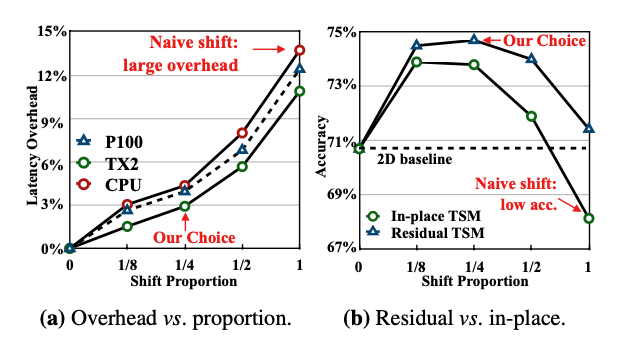
(a) 그림을 보시면 모두 shifting을 할 때 13.7%나 overhead가 발생한 것을 확인 할 수 있습니다.
(b) 그림을 보시면 Kinetics dataset을 기준으로 residual shift가 기존에 in-place shift보다 좋은 결과를 보임을 알 수 있습니다.
모든 채널을 인접 프레임에 shift한다 해도 shortcut connection 덕분에 residual shift가 더 높은 성능을 보였습니다.
그리고 각 방향마다 1/8 부분씩만 shift 시켜 총 1/4부분만 선택하는 것이 제일 높은 성능을 보임을 확인 했습니다.
[TSM Video Network]
온라인 TSM의 경우 미래의 채널을 들고 올 수 없으므로 1/8의 이전 값만 가지고 와 cashe에 저장한다. 그리고 1/8을 현재 프레임에 채우고 남은 7/8의 현재 프레임을 합친다. 장점은
- Low latency inference : 1/8을 계산 없이 사용할 수 있어 프레임 예측 latency를 줄인다.
- Low memory consumption : 적은 양만 캐쉬 메모리에 저장하므로 메모리 소비량이 적다.
- Multi-level temporal fusion : feature extraction이 끝난 이후나 중간이 아닌 모든 부분에서 temporal fusion이 가능하다.
Conclusion
TSM은 2D CNN의 핵심에 결합되어 추가적인 비용없이 시공간적 모델링이 가능하게 한다.
모듈은 시간축을 따라서 채널의 일부분을 이동시켜 인접 프레임의 정보를 교환한다.
